Представьте ситуацию: поисковой бот приходит к вам на сайт, сканирует контент и находит несколько одинаковых страниц. Как боту выбрать лучший вариант для ранжирования?
Бот доверится подсказкам, которые вы ему предоставите (если только вы не будете манипулировать алгоритмами поисковика). Если же вы не укажете, какой URL является каноническим (оригинальным / более важным для вас), бот сделает выбор за вас. А еще бот может расценить дублирующие страницы как одинаково важные. Тогда поисковик потратит краулинговый бюджет на повторяющийся контент, а прибыльные страницы могу в индекс так и не попасть.
Как избежать такого расклада? Ответ может показаться сложным, но в этой статье я объясню все просто. Итак, чтобы бот забрал в индекс выгодные страницы, их нужно канонизировать.
Читайте ниже, что это значит, как это нужно и не нужно делать.
Вы уверены, что у вас на сайте нет дубликатов?
Канонический URL – это страница, которую Google воспринимает как наиболее важную из нескольких дублирующихся URL-ов на сайте. Возможно вы думаете: «Я не копирую URL-ы у себя на сайте, поэтому мне не о чем беспокоиться». На самом деле дубликаты могут быть созданы автоматически. Например, поисковые роботы могут зайти на вашу страницу разными способами:
- Через протоколы HTTP и HTTPS:
http://www.yourwebsite.com
https://www.yourwebsite.com
- Через WWW и не WWW:
http://example.com
http://www.example.com/
Как лучше попасть к вам на сайт? Выберите лучший способ и не забудьте рассказать поисковым системам о своем выборе.
Рассмотрим еще один пример, когда множество дубликатов создается на коммерческом сайте автоматически. Сортировка товаров с помощью URL параметров по размеру, цвету, бренду и т. д. генерирует тысячи дубликатов. Например:
- yourwebsite.com/products/girls?category=dresses&color=white
yourwebsite.com/products/girls?category=dresses&color=black
- yourwebsite.com/dress?style=casual,long-sleeve
yourwebsite.com/dress?style=casual&style=long-sleeve)
Когда бот находит на сайте практически идентичный контент на разных URL-ах, авторитет сайта/позиция в органическом поиске снижается. Ведь поисковики ценят уникальный контент и ранжируют его выше, а дубликаты только тратят их ресурсы. Поэтому важно оптимальным способом разметить, какой контент на вашем сайте оригинальный, а какой нет. В статье я расскажу о четырех способах канонизации страниц. Мы поговорим о плюсах, минусах и особенностях использования каждого из них.
1. Тег Rel=canonical
Предположим, вы хотите сделать страницу https://yourwesite.com/page.php/ канонической. Для этого добавьте элемент link с атрибутом rel=»canonical» и ссылку на каноническую страницу в заголовок head всех дубликатов:
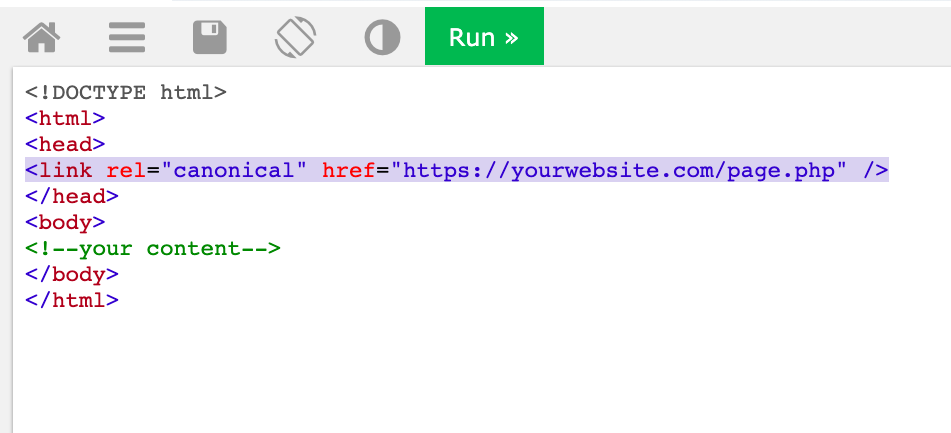
Если у канонической страницы есть вариант для мобильных устройств, добавьте элемент link с атрибутом rel=»alternate» и ссылкой на мобильную версию, например:
link rel=»alternate» media=»only screen and (max-width: 660px)» href=»https://m.yourwesite.com/page.php/»
Элемент link с атрибутом rel=»canonical» должны содержать абсолютный URL (полный), а не относительный (сокращенный) адрес.
2. Rel=canonical HTTP header
Тег Rel=canonical канонизирует HTML-страницы. Для других же форматов, как, например, PDF, Google рекомендует прописывать атрибут rel=canonical в HTTP-заголовке. PDF на сайте необходимо канонизировать потому, что боты просматривают и индексируют такие файлы так же, как и HTML страницы.
Этим способом можно воспользоваться только если у вас есть доступ к настройкам сервера. Не буду детально описывать процесс создания rel=canonical HTTP, так как необходимо углубиться в технические детали, и статья растянется страниц на 10. Оставляю ссылку на хорошую статью от MOZ со всеми нюансами внедрения rel=»canonical» HTTP Headers. Так же, как и в rel=canonical link, URL-ы в HTTP-заголовке должны быть абсолютными.
3. 301 редирект
301 статус код – это перенаправление пользователей и ботов на другой URL.
Когда лучше применить 301 статус код:
- смена домена сайта;
- для ошибки 404 и контента, утратившего актуальность, но имеющего релевантные ссылки и большой трафик;
- для контента, который переехал на другой URL навсегда.
4. Sitemap/Карта сайта
Sitemap, или по-русски карта сайта — это XML-файл с информацией о местонахождении URL-ов, дате их последнего обновления, частоте обновления и др. Вебмастер Google Джон Мюллер подтвердил, что страницы в картах сайта бот воспринимает как приоритетные для индексации и ранжирования.
«…мы используем URL-ы в sitemap как способ понять, какой URL следует считать каноническим для определенного контента».
Все страницы в этом файле бот считает каноническими.
Не добавляйте в Sitemap неканонические страницы.
Как делать НЕ нужно
1. НЕ канонизируйте несколько дубликатов разными способами. Предположим, у вас есть страницы А и В с одинаковым контентом. В страницы А вы добавляете тег rel=canonical, а страницу В указываете в sitemap (напоминаю, что все страницы в sitemap бот считает каноническими). Теперь бот запутался и потратил время и ресурсы, пытаясь понять, какой же контент считать оригинальным. Не надо так.
2. НЕ используйте rel=canonical tag/ HTTP header на страницах категорий товаров и фильтров. На коммерческих сайтах товары можно отсортировать по цвету, размеру, бренду и т.д. Если на каждой странице поставить тег canonical, то бот будет ходить по каждому параметру URL-а и тратить краулинговый бюджет там. Страницы сортировки лучше закрыть в robots.txt или в meta “noindex”, в зависимости от размера сайта и его специфики.
3. Не используйте robots.txt для канонизации. Директивы в robots.txt показывают, какие страницы/папки нужно краулить боту, а какие нет. Однако вебмастер Google не рекомендует таким образом канонизировать страницы, ведь бот не может даже зайти на страницу и понять, что это дубликат/оригинал.
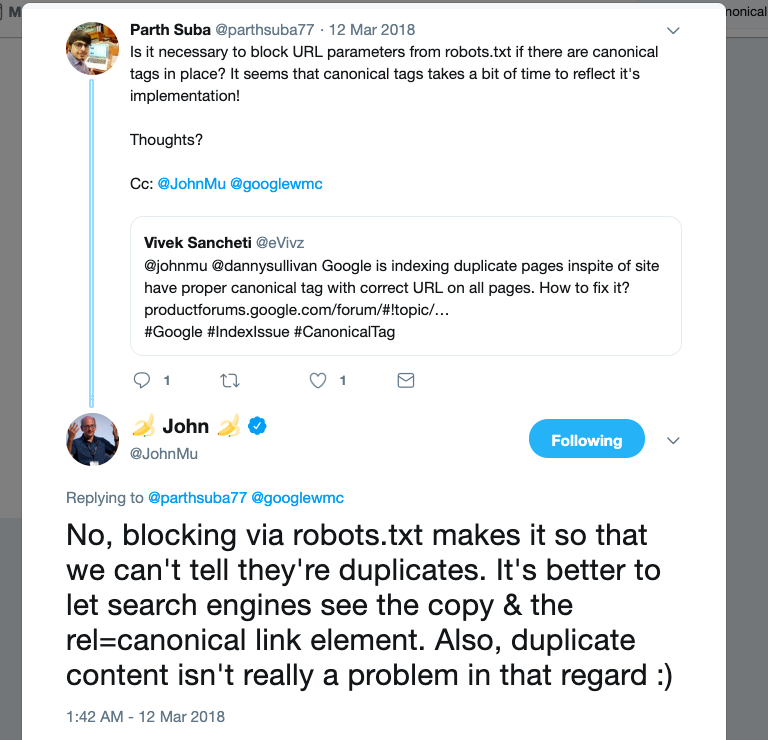
Источник: Twitter
Джон Мюллер:
Блокировка через robots.txt работает так, что мы даже не можем сказать, что это дубликаты. Лучше дать поисковой системе понять, что дубликаты есть, но ранжировать нужно страницу с rel=canonical элементом…
4. НЕ линкуйте дубликаты URL-ов внутри вашего сайта. Если вы канонизируете страницу, вы считаете ее более важной. Согласитесь, это странно, если вы ссылаетесь на неканонические/менее важные версии страниц.
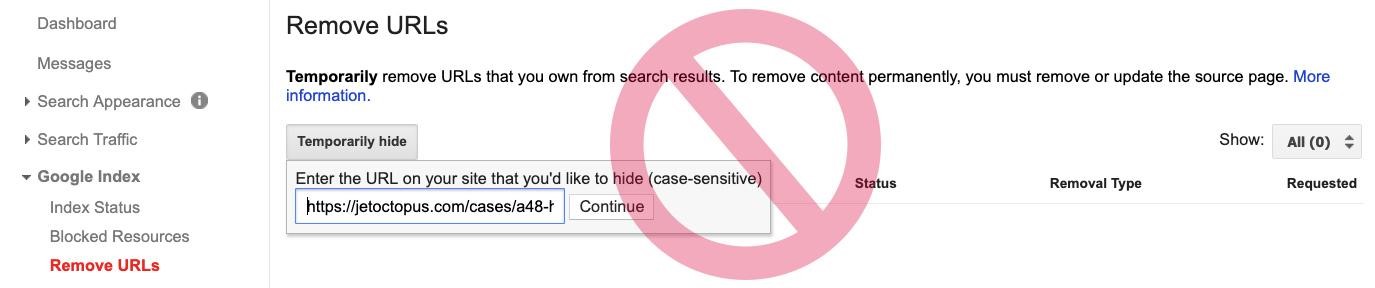
5. НЕ вписывайте дубликаты в URL removal tool в Google Search Console. Этот метод временно блокирует доступ ботов не только к дублям, но и к оригинальным версиям.
6. НЕ канонизируйте HTTP, если на сайте есть версия страницы с HTTPS-протоколом. Наличие SSL-сертификата (который поддерживает HTTP) является одним из факторов ранжирования Google, поэтому переход на протокол HTTPS повышает позиции страницы в поиске.
Коротко о главном
Итак, канонизация – это способ показать Google, какие страницы предпочтительно показывать в поисковой выдаче.
Используйте эти четыре рекомендованных Google способа канонизации:
- Rel=canonical tag – когда нужно канонизировать HTML страницы;
- Rel=canonical HTTP header – когда нужно канонизировать не HTML-файлы;
- 301 redirect – когда контент навсегда переезжает на другую страницу;
- XML Sitemap — чтобы перечислить все канонические страницы на сайте и облегчить боту сканирование (теги canonical также необходимо проставить).
Чтобы оптимизировать краулинговый бюджет и отправить прибыльные страницы в индекс, следуйте этим советам: